L'Analyse en Composantes Principales (ACP), également connue sous son acronyme anglais PCA (Principal Component Analysis), est une méthode de réduction de dimension largement utilisée en statistique descriptive. Son objectif principal est de simplifier l'analyse de données complexes en transformant un grand nombre de variables corrélées en un ensemble plus restreint de nouvelles variables décorrélées, appelées « composantes principales », tout en conservant un maximum d’informations. Cette transformation permet de visualiser des données initialement décrites sur plus de dimensions sur un graphique à 2 ou 3 dimensions, rendant ainsi les relations plus accessibles et compréhensibles.
Comprendre le Principe Fondamental de la Réduction de Dimension
Pour saisir le principe général de l'ACP, il est utile de commencer par un exemple simple : le passage de 2 dimensions à 1 dimension. Imaginez un tableau de données où chaque ligne représente une observation et chaque colonne une variable décrivant cette observation. D'un point de vue géométrique, chaque observation peut être représentée par un point (ou vecteur) dans un espace dont le nombre de dimensions correspond au nombre de variables. Si nous avons deux variables, nous pouvons visualiser ces observations comme des points dans un espace à deux dimensions. Ce graphique nous montre alors la proximité entre les observations.
De façon générale, les M observations d'un tableau de données peuvent être vues comme les M vecteurs dans un espace à N dimensions. En ajoutant une nouvelle variable, par exemple l'âge d'un individu, nous pouvons représenter les observations par un graphique à 3 dimensions. Cependant, avec plus de variables, et donc plus de dimensions, une visualisation directe devient problématique, voire impossible.
La solution à ce problème est la réduction de dimension. Il s'agit de transformer, par exemple, un tableau à 10 variables vers un tableau à 2 variables facilement représentable sur un graphique. Pour comprendre comment cette transformation fonctionne, partons d'un cas simple : la réduction d'un tableau à 2 dimensions vers un tableau à 1 dimension.
Pour réaliser cette transformation, il faut imaginer un axe qui passe au mieux par tous les points du nuage de données. Ensuite, chaque point est projeté sur cet axe. Cet axe, ou composante principale, est une nouvelle dimension fictive qui nous permet de représenter les observations sur 1 dimension.

Il est important de garder à l'esprit qu'il y a une perte d'information lorsque l'on réalise cette transformation. Des données différentes avant transformation peuvent aboutir aux mêmes résultats après projection. Plus les points sont corrélés entre eux, et plus l'information récupérée après la réduction de dimension sera grande. Dans différents scénarios, la réduction de dimensions peut amener aux mêmes résultats visuels, mais la différence réside dans la quantité d'information récupérée par la composante principale. L'ACP vise à maximiser cette information.
Les Fondements Mathématiques de l'ACP : Algèbre Linéaire et Statistique
Pour comprendre comment trouver ces axes par le calcul et généraliser la méthode à N dimensions, quelques prérequis d'algèbre linéaire sont nécessaires.
Vecteurs Propres et Valeurs Propres
En algèbre linéaire, la multiplication d'un vecteur $\vec{v}$ (un point) par une matrice $M$ aboutit à un nouveau vecteur $\vec{vt}$. Dans certains cas spécifiques, les vecteurs, appelés « vecteurs propres » (eigenvector), ne changent pas de direction après cette transformation. Chacun de ces vecteurs propres est associé à une « valeur propre » $\lambda$ (eigenvalue) qui indique le degré d'élongation ou de contraction du vecteur. Le vecteur transformé $\vec{vt}$ conserve sa direction, mais sa magnitude est modifiée par la valeur propre.

Les vecteurs propres d'une matrice sont cruciaux car ils représentent les directions dans l'espace où la transformation agit uniquement comme un étirement ou une compression.
Variance, Covariance et Matrice de Covariance
En statistique, la variance d'une variable x informe de la dispersion des données autour de leur moyenne. Plus la variance est élevée, plus les données sont étalées. La covariance entre deux variables indique la variance d'une variable x par rapport à une variable y. Elle renseigne sur le degré et la direction de la corrélation entre deux variables : une covariance positive indique que les variables varient dans le même sens, une covariance négative qu'elles varient en sens inverse, et une covariance proche de zéro suggère une faible corrélation linéaire.
La matrice de covariance est une matrice carrée qui contient l'ensemble des covariances entre toutes les paires de variables d'un jeu de données. Les éléments diagonaux de cette matrice sont les variances de chaque variable, tandis que les éléments hors diagonale sont les covariances entre les différentes paires de variables. Cette matrice est symétrique.
Le Lien Fondamental : Vecteurs Propres de la Matrice de Covariance
Le concept clé de l'ACP est le suivant : les axes d'une analyse en composante principale correspondent aux vecteurs propres de la matrice de covariance de vos données. Et la quantité d'information récupérée par chaque axe correspond aux valeurs propres de leurs vecteurs associés.
En d'autres termes, les vecteurs propres de la matrice de covariance de vos données représentent les directions de variance maximale dans l'ensemble des données. La première composante principale (PC1) sera le vecteur propre associé à la plus grande valeur propre, indiquant la direction de la plus grande variabilité. La deuxième composante principale (PC2) sera le vecteur propre associé à la deuxième plus grande valeur propre, et sera orthogonale (perpendiculaire) à la PC1, représentant la direction de la deuxième plus grande variabilité, et ainsi de suite.

Dans cet exemple, l'axe 1 récupère davantage d'information que l'axe 2, car la valeur propre associée à l'axe 1 est plus grande, indiquant une plus grande dispersion des données le long de cette direction.
Le Processus de l'Analyse en Composantes Principales en Cinq Étapes
L'Analyse en Composantes Principales (ACP) est une méthode structurée qui se déroule en plusieurs étapes pour réduire la dimensionnalité d'un volume de données tout en limitant les pertes d'informations. Voici les cinq étapes clés du processus :
Étape 1 : Normalisation des Variables
Cette étape est cruciale pour corriger la sensibilité de l'ACP à la variance des variables initiales. Elle consiste à transformer les données afin qu'elles soient placées à des échelles comparables et que leurs contributions soient équivalentes pour l'analyse. Sans normalisation, les variables avec des échelles plus grandes ou des variances plus élevées pourraient dominer les composantes principales, produisant ainsi des résultats biaisés. La normalisation typique implique de centrer les variables (soustraire la moyenne) et de les réduire (diviser par l'écart-type), ce qui donne des variables avec une moyenne de zéro et un écart-type de un.
Étape 2 : Calcul de la Matrice de Covariance
L'objectif de cette étape est de déterminer s'il existe des corrélations entre les variables du volume de données en entrée. Pour cela, il est nécessaire de calculer la matrice de covariance. Il s'agit d'un tableau qui affiche les corrélations entre les paires de variables. Lorsque le signe d'une covariance est positif, les deux variables sont corrélées positivement (elles varient dans le même sens). S'il est négatif, elles sont inversement corrélées (elles varient en sens inverse). Une covariance proche de zéro indique une faible corrélation linéaire. La matrice de covariance est essentielle car elle capture la structure de la dispersion et de la relation entre toutes les variables.
Étape 3 : Identification des Composantes Principales (Vecteurs et Valeurs Propres)
L'identification des composantes principales passe par le calcul des vecteurs propres et des valeurs propres de la matrice de covariance. Les vecteurs propres de la matrice de covariance représentent les directions des axes où il y a le plus de variances, ce sont donc les composantes principales. Chaque vecteur propre correspond à une direction dans l'espace de données le long de laquelle la variance est maximisée. Quant aux valeurs propres, elles fournissent la quantité de variance portée par chaque composante principale. En classant les valeurs propres par ordre décroissant, on obtient une hiérarchie des composantes principales : la première composante (associée à la plus grande valeur propre) explique la plus grande proportion de la variance totale, la deuxième explique la deuxième plus grande proportion, et ainsi de suite.
Étape 4 : Création du Vecteur des Caractéristiques
Après avoir identifié les composantes principales, il faut décider quelles composantes conserver et quelles composantes éliminer. Les composantes dont les valeurs propres sont faibles sont généralement considérées comme moins significatives car elles expliquent une faible proportion de la variance totale des données. Le choix du nombre de composantes à retenir est souvent guidé par des critères comme le pourcentage cumulé de variance expliquée (par exemple, retenir suffisamment de composantes pour expliquer 80% ou 90% de la variance totale) ou l'examen d'un graphique scree plot (qui représente les valeurs propres par ordre décroissant et aide à identifier un « coude » indiquant un point de coupure). Les facteurs choisis constituent le vecteur des caractéristiques, une matrice dont les colonnes sont les vecteurs propres des facteurs conservés. C'est la première étape concrète vers la réduction de dimensionnalité.
Étape 5 : Organisation des Données selon les Axes des Composantes Principales
L'objectif de cette étape est de transposer les données des axes d'origine vers ceux représentés par les composantes principales pour créer l'espace de données restreint. Il s'agit de projeter les observations originales sur le nouvel ensemble d'axes définis par les composantes principales choisies. Pour cela, il faut multiplier la transposition des données d'origine par la transposition du vecteur des caractéristiques. Les nouvelles coordonnées des observations dans cet espace réduit sont appelées les "scores" des composantes principales. Ce nouvel ensemble de données, de dimension inférieure, contient le maximum d'informations pertinentes des données originales, mais dans un format plus simple et plus facilement visualisable.
L'analyse en composante principale (ACP) expliquée d'une facon simple
Interprétation des Résultats de l'ACP
L’interprétation des résultats de l’ACP est une étape cruciale pour extraire des informations pertinentes des données transformées. Elle passe souvent par une représentation graphique des variables initiales et des observations sur des plans factoriels.
Critères d'Interprétation
L’analyse des données se base en général sur les deux ou trois premiers plans factoriels, à condition qu’ils représentent la majeure partie de la variance du nuage de points. Voici trois critères permettant d’interpréter les résultats :
- Distance entre un point et l’axe (Contributions des variables aux composantes) : Pour interpréter chaque composante principale, il faut examiner la valeur et la direction des coefficients des variables initiales. Plus la valeur absolue du coefficient est élevée et plus la variable correspondante est importante dans le calcul de la composante. Les points les plus intéressants à observer sont ceux qui sont proches d’un axe et loin de l’origine. On dit qu’il est corrélé avec l’axe. Cette corrélation représente la qualité de représentation du point sur l’axe. Lorsque sa valeur tend vers 0, le point n’est pas du tout corrélé avec l’axe. Lorsqu’elle est proche de 1 (ou -1), le point est alors bien représenté sur l’axe et contribue fortement à cette composante. La valeur absolue à partir de laquelle un coefficient peut être considéré comme important est subjective et nécessite des connaissances spécialisées du domaine.
- Distance entre un point et l’origine : L’interprétation des points situés près du centre est incertaine, car ils sont mal représentés sur le plan factoriel. Cela signifie que leur position sur ce plan particulier ne reflète pas pleinement leur variabilité par rapport aux autres composantes. Lorsque deux points situés loin du centre sont proches, il est fort probable qu’ils soient similaires. Cependant, il faut considérer leur placement par rapport à tous les axes (pas seulement les deux ou trois premiers) pour conclure qu’ils sont vraiment proches et partager des caractéristiques similaires.
- Rotation des facteurs : Pour simplifier la lecture des poids des variables, il est possible de procéder à une rotation des facteurs. Cela revient à faire pivoter virtuellement les axes des facteurs autour du point d’origine pour mieux redistribuer la variance que l’on cherche à expliquer. Cette méthode de rotation permet de mieux distribuer la variance expliquée entre les composantes, rendant l'interprétation des poids des variables sur chaque composante plus claire et plus distincte.
Exemple d'Interprétation avec des Données Financières
Considérons une analyse des valeurs et vecteurs propres d'une matrice de corrélation pour des données financières :
| Valeur propre | Proportion | Cumulée |
|---|---|---|
| 3,5476 | 0,443 | 0,443 |
| 2,1320 | 0,266 | 0,710 |
| 1,0447 | 0,131 | 0,841 |
| 0,5315 | 0,066 | 0,907 |
| 0,4112 | 0,051 | 0,958 |
| 0,1665 | 0,021 | 0,979 |
| 0,1254 | 0,016 | 0,995 |
| 0,0411 | 0,005 | 1,000 |
| Variable | PC1 | PC2 | PC3 | PC4 | PC5 | PC6 | PC7 | PC8 |
|---|---|---|---|---|---|---|---|---|
| Revenu | 0,314 | 0,145 | -0,676 | -0,347 | -0,241 | 0,494 | 0,018 | -0,030 |
| Formation | 0,237 | 0,444 | -0,401 | 0,240 | 0,622 | -0,357 | 0,103 | 0,057 |
| Age | 0,484 | -0,135 | -0,004 | -0,212 | -0,175 | -0,487 | -0,657 | -0,052 |
| Résidence | 0,466 | -0,277 | 0,091 | 0,116 | -0,035 | -0,085 | 0,487 | -0,662 |
| Emploi | 0,459 | -0,304 | 0,122 | -0,017 | -0,014 | -0,023 | 0,368 | 0,739 |
| Épargne | 0,404 | 0,219 | 0,366 | 0,436 | 0,143 | 0,568 | -0,348 | -0,017 |
| Crédits | -0,067 | -0,585 | -0,078 | -0,281 | 0,681 | 0,245 | -0,196 | -0,075 |
| Cartes crédit | -0,123 | -0,452 | -0,468 | 0,703 | -0,195 | -0,022 | -0,158 | 0,058 |
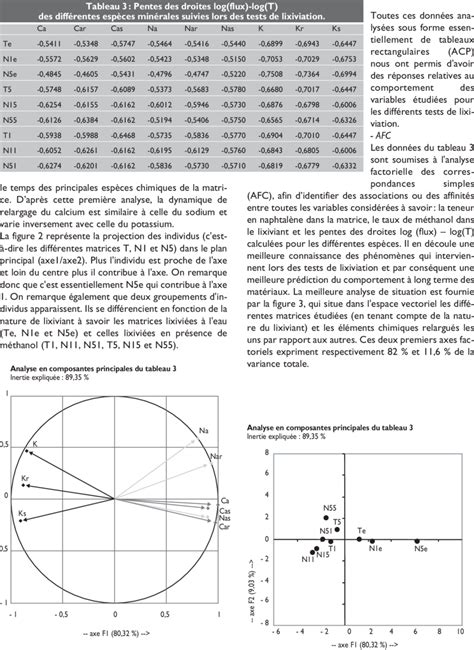
Dans ces résultats, la première composante principale (PC1) présente une forte association positive avec les variables Age (0,484), Résidence (0,466), Emploi (0,459) et Épargne (0,404). PC1 mesure donc principalement la stabilité financière à long terme. La deuxième composante (PC2) présente une forte association négative avec Crédits (-0,585) et Cartes crédit (-0,452), et mesure donc principalement l'historique de crédit du candidat. La troisième composante (PC3) présente une forte association négative avec Revenu (-0,676), Formation (-0,401) et Cartes crédit (-0,468), et mesure donc principalement les qualifications du candidat en matière de formation et de revenus. Le diagramme des contributions peut également présenter visuellement ces résultats.
Généralisation à N Dimensions et Applications Pratiques
En généralisant, pour réduire un espace à N dimensions vers un espace à K dimensions, il suffit de faire la projection des points de l'espace de départ sur les K premiers vecteurs propres qui récupèrent le maximum d'information, c'est-à-dire ceux qui ont les valeurs propres les plus grandes.
Exemple avec le Jeu de Données Iris
Nous pouvons illustrer cela en utilisant le jeu de données Iris, qui contient 50 observations de fleurs et 4 variables (ou 4 dimensions). En réduisant ces 4 dimensions sur un espace à deux dimensions, nous obtenons un graphique qui représente la projection des observations. Ces deux axes (PC1 et PC2) sont accompagnés du pourcentage d'information récupéré grâce aux valeurs propres. Le premier axe récupère 92,46% de l'information, puis le second récupère 5,31%. Au total, les deux premiers axes ont récupéré plus de 97% de l'information. Et comme les couleurs nous le montrent, nous constatons que les fleurs de la même espèce sont à proximité dans cet espace bidimensionnel, ce qui facilite leur classification visuelle.
Rôle de l'ACP dans l'Analyse de Données
L’ACP peut être considérée comme une méthode de projection. Elle combine deux approches : une approche géométrique avec la représentation des variables dans un nouvel espace selon des directions d’inertie maximale, et une approche statistique avec la recherche d’axes indépendants décrivant la variance. L’Analyse en Composantes Principales répond à trois principaux objectifs :
- Comprendre les corrélations entre un ensemble de variables.
- Créer des instruments pour l’analyse de données non mesurables directement.
- Compresser sans perte de données les informations relatives à un grand nombre de variables dans un espace plus restreint.
L'ACP est donc un outil indispensable pour tous les futurs experts en data science, IA ou cybersécurité.
Domaines d'Application de l'ACP
L’Analyse en Composantes Principales est une technique polyvalente utilisée dans de nombreux secteurs et disciplines, grâce à sa capacité à simplifier des données complexes et à révéler des structures cachées.
Applications Diverses
- Marketing digital : L'ACP est utilisée pour la segmentation de la clientèle, le ciblage publicitaire et les études de marché. Par exemple, elle peut aider à identifier les profils de consommateurs en fonction de leurs comportements d'achat ou de leurs préférences, permettant des campagnes marketing plus ciblées.
- Biostatistique : Elle est appliquée dans la modélisation de données médicales, l'analyse de l'expression génique, et la classification de maladies. En médecine nucléaire, cette méthode de réduction de dimensionnalité peut procéder à l’analyse de séries dynamiques d’images, comme dans la prédiction du cancer du sein à l’aide de l’analyse en composantes principales et de la régression logistique.
- Apprentissage automatique (Machine Learning) : L'ACP est essentielle pour l'optimisation des modèles d'IA, le prétraitement des données pour les algorithmes d'apprentissage non supervisé et supervisé, la réduction de la complexité des données pour éviter le sur-apprentissage, et l'extraction de caractéristiques informatives. Elle minimise ou élimine les problèmes courants tels que la multicolinéarité et le surajustement.
- Cybersécurité : Elle permet la détection d'anomalies dans les données réseau et l'identification de modèles de comportement malveillants.
- Traitement d'image : L'ACP a d'autres applications en informatique, notamment dans le traitement d'image, la compression et la réduction du bruit. En effet, si vous faites une PCA sur une image, vous récupérez le maximum d'information utile sans le bruit. En faisant l'inverse d'une PCA, vous reconstituerez alors une image débruitée.
- Sociologie et Sciences Sociales : Pour analyser des enquêtes avec de nombreuses questions et identifier des dimensions sous-jacentes (par exemple, des facteurs socio-économiques ou des attitudes).
L'ACP est donc un outil clé pour les métiers du digital et de la data, offrant une approche puissante pour analyser et comprendre des ensembles de données de grande dimension.
Avantages de l'ACP et Comparaison avec d'Autres Méthodes
L'Analyse en Composantes Principales se distingue par plusieurs avantages significatifs par rapport à d'autres méthodes d'analyse de données, tout en ayant ses propres spécificités.
Avantages Clés de l'ACP
- Réduction de la complexité des données : L'ACP simplifie un grand nombre de variables sans perte d’information significative, en projetant les données dans un sous-espace de dimension inférieure.
- Optimisation des modèles de données : Elle évite le sur-apprentissage en permettant de travailler dans une dimension réduite. La simplification des données influe positivement sur la puissance de calcul et fait gagner du temps.
- Mieux visualiser les corrélations : L'ACP révèle les liens entre variables et individus dans un espace graphique clair, ce qui aide à l'interprétation des structures de données. Elle permet de visualiser les corrélations entre variables, mais aussi d'identifier des observations atypiques.
- Extraction de caractéristiques : L'ACP est une technique d'extraction de caractéristiques. Elle produit de nouvelles variables (les composantes principales) qui sont des combinaisons linéaires des variables initiales, et qui présentent la variance maximale. Ces nouvelles variables sont décorrélées entre elles.
Alternatives à l'ACP
L'ACP est une technique linéaire, ce qui signifie qu'elle est mieux adaptée aux jeux de données présentant des relations linéaires entre les variables. Cependant, il existe d'autres méthodes factorielles ou de réduction de dimensionnalité, chacune avec ses propres forces et applications spécifiques :
- Analyse Factorielle des Correspondances (AFC) : Cette technique s’appuie sur un tableau croisant deux variables qualitatives. Dans ce cas, les individus et les variables jouent des rôles symétriques. L’AFC permet d’analyser et de classer l’information contenue dans un tableau de données catégoriques.
- Analyse des Correspondances Multiples (ACM) : L’ACM est également consacrée aux variables qualitatives, mais pour un tableau de données où des individus sont décrits par un ensemble de variables qualitatives multiples. Elle est souvent perçue comme proche de l’ACP, où les variables quantitatives sont remplacées par des variables qualitatives.
- Analyse Factorielle de Données Mixtes (AFDM) : L’AFDM utilise un tableau dans lequel des individus sont décrits par un ensemble de variables quantitatives et qualitatives. Elles sont traitées simultanément dans le processus, permettant de déceler la proximité entre les variables et les observations, quelle que soit leur nature.
- Analyse Factorielle Multiple (AFM) : Cette méthode permet d’étudier un type de tableau dans lequel un ensemble d’individus est décrit par un ensemble de variables structurées en groupes. Elles peuvent être de type quantitatif, qualitatif ou les deux. En fonction du type de variable, l’AFM est une extension de l’ACP, l’ACM ou l’AFDM, adaptée à des structures de données plus complexes.
- Analyse Discriminante Linéaire (ADL) : Contrairement à l'ACP, qui est une méthode non supervisée, l'ADL est une technique d'apprentissage supervisé. Elle vise à trouver une projection des données qui maximise la séparabilité entre différentes classes, plutôt que de maximiser la variance totale comme l'ACP.
- t-SNE (t-distributed Stochastic Neighbor Embedding) et UMAP (Uniform Manifold Approximation and Projection) : Ces techniques sont des méthodes non linéaires. Elles sont particulièrement efficaces pour la visualisation de jeux de données présentant des relations non linéaires ou complexes entre les variables, en se concentrant sur la préservation de la structure locale des données. Elles sont souvent plus coûteuses en calcul que l'ACP, surtout pour de très grands jeux de données, mais offrent des visualisations plus nuancées des regroupements.
En conclusion, bien que l'ACP soit une méthode puissante et fondamentale pour la réduction de dimension, le choix de la technique la plus appropriée dépendra de la nature des données, des objectifs de l'analyse, et du type de relations que l'on souhaite explorer.
tags: #analyse #en #compostante #principale